En quoi l'implémentation interne de LinkedHashMap est-elle différente de l'implémentation HashMap?
J'ai lu que HashMap a l'implémentation suivante:
main array
↓
[Entry] → Entry → Entry ← linked-list implementation
[Entry]
[Entry] → Entry
[Entry]
[null ]
Ainsi, il a un tableau d'objets Entry.
Des questions:
Je me demandais comment un index de ce tableau pouvait stocker plusieurs objets Entry dans le cas d'un même hashCode mais d'objets différents.
En quoi est-ce différent de l'implémentation de
LinkedHashMap? Son implémentation de liste doublement liée de la carte, mais maintient-elle un tableau comme ci-dessus et comment stocke-t-elle les pointeurs vers l'élément suivant et précédent?
Ainsi, il a un tableau d'objets
Entry.
Pas exactement. Il a un tableau de Entry objet chaînes. UNE HashMap.Entry objet a un champ next permettant aux objets Entry d'être chaînés en tant que liste chaînée.
Je me demandais comment un index de ce tableau peut stocker plusieurs objets
Entrydans le cas d'un même hashCode mais d'objets différents.
Parce que (comme le montre l'image de votre question) les objets Entry sont chaînés.
En quoi est-ce différent de l'implémentation de
LinkedHashMap? Son implémentation de liste doublement liée de la carte, mais maintient-elle un tableau comme ci-dessus et comment stocke-t-elle les pointeurs vers l'élément suivant et précédent?
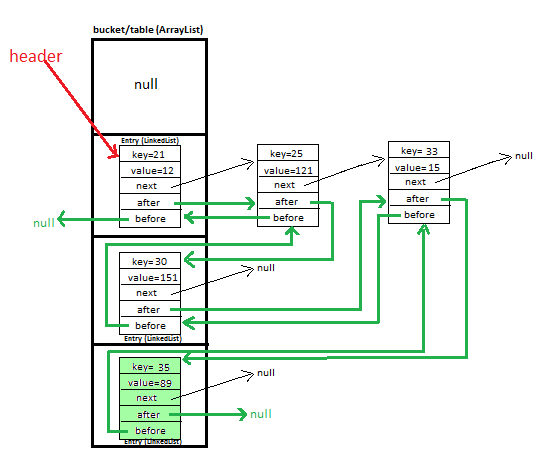
Dans l'implémentation LinkedHashMap, le LinkedHashMap.Entry classe étend le HashMap.Entry class, en ajoutant les champs before et after. Ces champs sont utilisés pour assembler le LinkedHashMap.Entry objets dans une liste indépendante à double liaison qui enregistre l'ordre d'insertion. Ainsi, dans la classe LinkedHashMap, les objets d'entrée sont dans deux chaînes distinctes:
une chaîne de hachage à liaison unique accessible via le tableau de hachage principal, et
une liste séparée et doublement liée de toutes les entrées qui est conservée dans l'ordre d'insertion des entrées.
HashMap ne maintient pas l'ordre d'insertion, donc ne conserve aucune liste doublement liée.
La caractéristique la plus saillante de LinkedHashMap est qu'il maintient l'ordre d'insertion des paires clé-valeur. LinkedHashMap utilise doublement Linked List pour ce faire.
L'entrée de LinkedHashMap ressemble à ceci:
static class Entry<K, V> {
K key;
V value;
Entry<K,V> next;
Entry<K,V> before, after; //For maintaining insertion order
public Entry(K key, V value, Entry<K,V> next){
this.key = key;
this.value = value;
this.next = next;
}
}
En utilisant avant et après - nous gardons une trace de l'entrée nouvellement ajoutée dans LinkedHashMap, ce qui nous aide à maintenir l'ordre d'insertion.
Avant de se référer à l'entrée précédente et après se réfère à l'entrée suivante dans LinkedHashMap.
Pour des diagrammes et des explications étape par étape, veuillez vous référer à http://www.javamadesoeasy.com/2015/02/linkedhashmap-custom-implementation.html
Merci..!!
Prenez un regardez pour vous-même. Pour référence future, vous pouvez simplement google:
Source Java LinkedHashMap
HashMap utilise un LinkedList pour gérer les collisions, mais la différence entre HashMap et LinkedHashMap est que LinkedHashMap a un ordre d'itération prévisible, qui est obtenu grâce à une liste supplémentaire à double liaison, qui maintient généralement l'ordre d'insertion des clés. L'exception est lorsqu'une clé est réinsérée, auquel cas elle revient à la position d'origine dans la liste.
Pour référence, l'itération via un LinkedHashMap est plus efficace que l'itération via un HashMap, mais LinkedHashMap est moins efficace en mémoire.
Au cas où cela ne serait pas clair à partir de mon explication ci-dessus, le processus de hachage est le même, vous obtenez donc les avantages d'un hachage normal, mais vous obtenez également les avantages de l'itération comme indiqué ci-dessus, car vous utilisez une liste doublement liée à maintenir l'ordre de vos objets Entry, qui est indépendant de la liste chaînée utilisée lors du hachage pour les collisions, au cas où cela serait ambigu ..
EDIT: (en réponse au commentaire de OP):
Un HashMap est soutenu par un tableau, dans lequel certains emplacements contiennent des chaînes d'objets Entry pour gérer les collisions. Pour parcourir toutes les paires (clé, valeur), vous devez parcourir tous les emplacements du tableau, puis passer par LinkedLists; par conséquent, votre temps global serait proportionnel à la capacité.
Lorsque vous utilisez un LinkedHashMap, tout ce que vous avez à faire est de parcourir la liste doublement liée, de sorte que le temps global est proportionnel à la taille.
Puisqu'aucune des autres réponses n'explique réellement comment une telle chose pourrait être implémentée, je vais essayer.
Une façon serait d'avoir des informations supplémentaires dans la valeur (de la paire clé-> valeur) non visibles pour l'utilisateur, qui avaient une référence à l'élément précédent et suivant inséré dans la carte de hachage. Les avantages sont que vous pouvez toujours supprimer des éléments en temps constant, la suppression d'un hashmap est un temps constant et la suppression d'une liste liée est dans ce cas parce que vous avez une référence à l'entrée. Vous pouvez toujours insérer en temps constant car l'insertion de la carte de hachage est constante, la liste liée n'est pas normalement, mais dans ce cas, vous avez un accès en temps constant à un point de la liste liée afin que vous puissiez insérer en temps constant, et enfin la récupération est temps constant car il vous suffit de gérer la partie de la carte de hachage de la structure.
Gardez à l'esprit qu'une telle structure de données n'est pas gratuite. La taille de la carte de hachage augmentera considérablement en raison de toutes les références supplémentaires. Chacune des principales méthodes sera légèrement plus lente (pourrait avoir de l'importance si elles sont appelées à plusieurs reprises). Et l'indirection de la structure de données (je ne sais pas si c'est un vrai terme: P) est augmentée, bien que cela ne soit pas aussi important car les références sont garanties de pointer vers des éléments à l'intérieur de la carte de hachage.
Le seul avantage de ce type de structure étant qu'il préserve l'ordre, soyez prudent lorsque vous l'utilisez. Aussi lors de la lecture de la réponse, gardez à l'esprit que je ne sais pas comment c'est implémenté mais c'est comme ça que je le ferais si on me confiait la tâche.
Sur le Oracle docs il y a une citation confirmant certaines de mes suppositions.
Cette implémentation diffère de HashMap en ce qu'elle maintient une liste doublement liée parcourant toutes ses entrées.
Une autre citation pertinente du même site Web.
Cette classe fournit toutes les opérations Map facultatives et autorise les éléments nuls. Comme HashMap, il fournit des performances à temps constant pour les opérations de base (ajouter, contenir et supprimer), en supposant que la fonction de hachage disperse les éléments correctement entre les compartiments. Les performances sont probablement légèrement inférieures à celles de HashMap, en raison des dépenses supplémentaires liées à la maintenance de la liste liée, à une exception près: l'itération sur les vues de collection d'un LinkedHashMap nécessite un temps proportionnel à la taille de la carte, quelle que soit sa capacité . L'itération sur un HashMap est susceptible d'être plus coûteuse, nécessitant un temps proportionnel à sa capacité.